Before I start working on I’d like to summarise things that should be done for interframe encoding.
Read the rest of this entry »
VP6 — interframe encoder roadmap
September 11th, 2021VP6 — simple intraframe encoder, part 2
September 10th, 2021At last I have a working intraframe VP6 encoder. And the encoded data is decoded fine by the reference decoder as well as by open-source ones. So here I’ll describe what I had to do in order to achieve that result.
Read the rest of this entry »
VP6 — simple intraframe encoder, part 1
September 5th, 2021I admit that I haven’t spent much time on writing encoder but I still have some progress to report.
Read the rest of this entry »
VP6 — bool coder
August 29th, 2021Today I’ll try to tell the principles behind bool coder in VP6 (actually VP5-VP9) and how it all should work in the encoder. As usual, let’s start with the theory.
Read the rest of this entry »
VP6 encoding — DCT
August 27th, 2021Transform is one of the essential parts of typical video codec, lots of them can be described as e.g. “DCT-based video codec using X coding [and additional features like …]”. That is why I’m starting with it.
Read the rest of this entry »
Starting work on VP6 encoder
August 26th, 2021It is no secret (not even to me) that I suck at writing encoders. But with NihAV being developed exactly for trying new things and concepts, why not go ahead and try writing an encoder? It is not for having an encoder per se but rather a way to learn how things work (the best way to learn things is to try them yourself after all).
There are several reasons why I picked VP6:
- it is complex enough to have different concept of encoding to try on it;
- in the same time it’s not that complex (just DCT, MC, bool coder and no B-frames, complex block partitioning or complex context-adaptive coding);
- there’s no opensource encoders for it;
- there’s a decoder for it in
NihAValready; - this is not a toy format so it may be of some use for me later.
Of course I’m aware of other attempts to bring us an opensource VP6 encoder and that they all failed, but nothing prevents me from failing at it myself and documenting my path so others might fail at it faster and better.
Speaking of documenting, here’s a roadmap of things I want to play with (or played with already) and report how it went:
- DCT;
- bool coder;
- simple intraframe coding;
- motion estimation (including fast search and subpixel precision);
- rate distortion optimisation;
- rate control.
Hopefully the post about DCT will come tomorrow.
P.S. Why I declare this in public? So that I won’t chicken out immediately.
PACo done!
August 24th, 2021As I said in the previous post, I was looking at PACo format with an enhanced RLE compression. It turned out to be even more curious than I expected.
Beside the normal RLE mode it has pair and quad RLE (where you repeat two or four pixels) and long operation mode where you can do single/pair/quad RLE, copy or skip using 12-bit number. But it turns out it also has a compact RLE mode that works on a single line using a set of 16 colours and putting operation code, length and colour index into a single nibble instead of a byte (and it also has its own long mode where lengths are using a whole byte!).
That’s the variety I miss in modern video codecs.
Looking at PACo
August 23rd, 2021I was asked to look at this format used at least in Iron Helix game and it’s a somewhat interesting format.
It turned out to come from Macintosh. There are two small signs hinting on it: big-endian numbers inside the file and the fact it uses default QuickTime palette.
The container is simple but functional: there’s a header containing frame sizes among other thing, frame consisting of several records (usually it’s just video data and frame data end marker; the first frame has initalisation data chunk as well). Frames can have one of two compression methods and coded area size and offset.
Compression is just a slightly advanced RLE: codes 0x01–0x7F mean copying data, codes 0x80–0xFD are used to signal runs, code 0x00 is used to code long operations, code 0xFE is used to signal skips, code 0xFF is used for either runs of pairs or quads of pixels (depending on the run length). Each line is coded independently (i.e. runs or copies can’t go past the current line end). So what’s the tricky part there?
That’s compression method 1 and it works quite well. Compression method 2 is essentially the same but it codes lines in interlaced manner for which I haven’t managed to get a good picture in all cases yet (it seems to code more lines than declared sometimes and interlacing seems to be dependent on both decoded are position and height). But hopefully it won’t take long and I can document it in The Wiki.
Some words on QT Animation (SMC) codec
August 10th, 2021A recent question about buggy SMC decoding led me deep into QuickTime specification to look at the codec missing opcode. And there are some noteworthy things here as well.
Back in the day there was the multimedia player for Unix called XAnim. Its last release was in 1999—before other opensource multimedia player projects have started! It was both feature-rich (e.g. it could step frames forward and backwards, something that not all current media players can do) and had an excellent codec support for the time.
Somehow its author reverse engineered (long before the era of decompilers too) a lot of codecs and somehow managed to obtain the sources for e.g. Indeo and while he could not provide them, he offered them for a wide variety of architectures—Alpha, MIPS, Sparc, PowerPC, x86. It was a treasure trove for formats and lots of the decoders were ported to other projects (even I did that for one or two codecs) and binary codecs were a great help in reverse-engineering efforts as well.
Now to SMC itself. Formally it’s QuickTime Animation codec but people call it after its FOURCC which is “smc “, probably after the author’s initials.
Opensource SMC decoders come from the same source (I based mine on the description in The Wiki but you can guess what that description is based on; and yes, back in the day e.g. MPlayer and Xine had their own decoders for various codecs before relying on libavcodec for everything). After looking at the binary specification I can say it looks exactly like it was reverse engineered from it directly (it has the same logic and data types but lacks sensible names). Anyway, the thing is that it does not handle opcode 0xF0 and I finally had an occasion to look at it.
I took QuickTime 6.3 binary specification for Windows (somehow the decoder ended in QuickTimeInternetExtras.qtx) and looked inside. It turns out that there are several decoding functions there (for different output formats) but they all do the same: handle 0xF0 opcode in exactly the same way as 0xE0 opcode (raw blocks), there are no differences there whatsoever.
That’s one mystery less, even if the answer is a bit disappointing. At least I could reminisce about good old times hardly anybody else remembers.
Playing with trellis and encoding
August 8th, 2021I said before I want to play with encoding algorithms within NihAV and here’s another step (a previous major step was vector quantisation and a simple Cinepak encoder using it). Now it’s time for trellis search for encoding.
The idea by itself is very simple: you want to encode a sequence optimally (or decode transmitted sequence with distortions), so you represent your data as a set of possible states for each sample and search a path from one state to another with the minimum error. Since each state of the sample is connected with all states of the previous samples, its graph looks like a trellis:
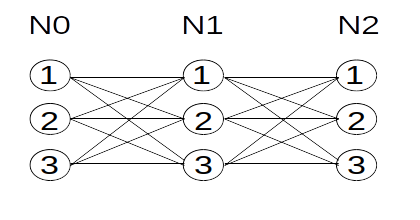
The search itself is performed by selecting for each state a transition from a previous state that gives minimal error, then selecting a state with the least error for the last sample and tracing back the path that lead to it from the beginning. You just need to store the pointer to the previous state, error value and whatever decoder state you require.
I’ve chosen IMA ADPCM encoder as a test playground since it’s simple but useful. The idea of the format is very simple: you have a state consisting of current sample value and step size used as a multiplier for the transmitted 4-bit difference value; you reconstruct the difference, add it to the previous stored value, and correct step size (small delta—decrease step, large delta—increase step). You have 16 possible states for each sample which makes the search take not so long time.
There’s another tricky question of selecting initial step size (it will adapt to the samples but you need to start with something). I select it to be close to the difference between first and second samples and actually abuse first state to store not the index of the previous state but rather a step index. This way I start with (ideally) 16 different step sizes around the current one and can use the one that gives slightly lower error in the end.
And another fun fact: this way I can use just the code for decompression of single ADPCM sample and I don’t require actual code for compression—it traverses through all possible compressed codes already.
I hope this demonstrates that it’s an easy method that improves quality significantly (I have not conducted proper testing but a from a quick test it reduced mean squared error for me by 10-20%).
It should also come in handy for video compression but unfortunately rate distortion optimisation does not look that easy…