I said before I want to play with encoding algorithms within NihAV and here’s another step (a previous major step was vector quantisation and a simple Cinepak encoder using it). Now it’s time for trellis search for encoding.
The idea by itself is very simple: you want to encode a sequence optimally (or decode transmitted sequence with distortions), so you represent your data as a set of possible states for each sample and search a path from one state to another with the minimum error. Since each state of the sample is connected with all states of the previous samples, its graph looks like a trellis:
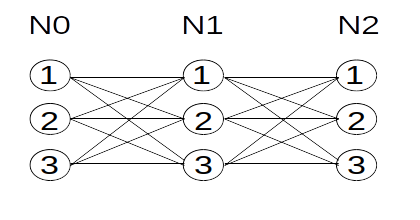
The search itself is performed by selecting for each state a transition from a previous state that gives minimal error, then selecting a state with the least error for the last sample and tracing back the path that lead to it from the beginning. You just need to store the pointer to the previous state, error value and whatever decoder state you require.
I’ve chosen IMA ADPCM encoder as a test playground since it’s simple but useful. The idea of the format is very simple: you have a state consisting of current sample value and step size used as a multiplier for the transmitted 4-bit difference value; you reconstruct the difference, add it to the previous stored value, and correct step size (small delta—decrease step, large delta—increase step). You have 16 possible states for each sample which makes the search take not so long time.
There’s another tricky question of selecting initial step size (it will adapt to the samples but you need to start with something). I select it to be close to the difference between first and second samples and actually abuse first state to store not the index of the previous state but rather a step index. This way I start with (ideally) 16 different step sizes around the current one and can use the one that gives slightly lower error in the end.
And another fun fact: this way I can use just the code for decompression of single ADPCM sample and I don’t require actual code for compression—it traverses through all possible compressed codes already.
I hope this demonstrates that it’s an easy method that improves quality significantly (I have not conducted proper testing but a from a quick test it reduced mean squared error for me by 10-20%).
It should also come in handy for video compression but unfortunately rate distortion optimisation does not look that easy…