In my previous post I’ve described NAScale ideas and here I’d like to give more detailed overview on the internal design.
Basically, it builds a processing pipeline (or chain, I insist on terminology being inconsistent) that takes input frame, does some magic on it and outputs the result.
Let’s start with looking at typical pipeline for processing packed formats:
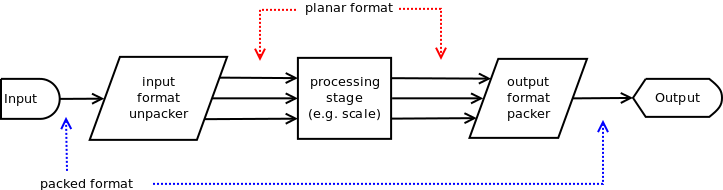
And that should be a pipeline for the worst case since we don’t need input unpacker when it’s not packed (and same for the output), and processing stage might be not needed either (if we simply repack formats), and in some cases one stage will be enough.
My approach for pipeline construction is rather simple:
- we have special modules (called kernels) that are used to construct pipeline stages;
- all those modules are divided into three categories (input handling, output handling and intermediate filters)
- all stages input and output (except for the source and destination handlers) should be planar and either 8- or 16-bit native endian (the less variations in input and output one has to handle the better).
Efficiency considerations tell us there will be special kernels for combining format conversion into one stage (like super-optimised rgb24tovyuy) but generic pipeline able to hold almost any format should have one universal input unpacker and one universal output packer.
Let’s review how pipeline building should work.
Unfortunately, my prototype can build only several pipelines for very specific cases but the principle stays the same.
Zeroeth stage: check if we are dealing with completely the same input and output formats and dimensions and then just apply memcopy (the kernel is obviously called murder).
Even if formats are the same we may need to scale the input or convert it to account for colourspace details etc etc.
Right from the start we need to check if we deal with a packed format and insert unpack stage or skip it and feed input directly to the processing stage.
On one hand there might be need for input stage converting planar 12-bit input into proper 16-bit input for processing stages, on the other hand it might be skipped in some cases (for efficiency reasons).
And then you should add a next stage but don’t forget about intermediate planar buffers—they should be allocated for the stage so that the following stage will know where to read its input from.
Now it’s probably a good time to mention that during pipeline construction we should keep track of current format and thus each stage construction should modify it to let the next stage know what input format it should expect (e.g. input was packed 10-bit BGR, unpack makes it into 16-bit planar RGB, scale changes nothing but dimensions and rgb2yuv converts it to 16-bit YUV and pack converts it into output format like YUYV).
Don’t forget that for clarity and simplicity all stages get pointers to the components in the order of the colourspace model components, i.e. it’s always R,G,B even if the input was packed BGR32 (the pointers will point to the start positions of the component in a packed input in that case), and that applies to both input and output.
Kernels are standalone modules that prepare contexts and processing functions but intermediate and scratch buffers are allocated by NAScale core during pipeline construction.
Often you don’t need scratch buffers but when your stage outputs only three components (i.e. RGB) and the next stage demands four (i.e. RGBA) you should allocate a scratch buffer for that stage to use as an input (again, for efficiency reasons we might want to pass through buffers from the previous stage that are not touched in the current one but I’m not sure how to implement that yet).
Developing all of this should be not that hard though and most time should be spent on optimising common cases instead.
And that’s all for now.